| python数据分析(二) python numpy | 您所在的位置:网站首页 › python 计算数组大小 › python数据分析(二) python numpy |
python数据分析(二) python numpy
|
Numpy
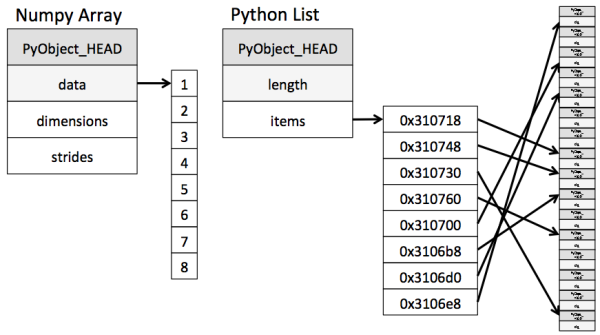
numpy是数值计算最重要的基础包,几乎所有的科学运算的模块底层所用的都是numpy数组。 Numpy本身没有提供多么高级的数据分析功能,他所提供的功能主要是: 1.具有矢量算术运算(用数组表达式代替循环的做法通常称为矢量化),矢量化计算因为不使用循环,因此速度会快1到两个数量级 2.广播。(不同大小的数组之间的运算) 3.提供了对整组数据进行快速运算的标准函数。 4.用于读写磁盘数据的工具以及操作内存映射文件的工具(将数组保存及读取为文件,mmap系统调用使得进程之间通过映射同一个普通文件实现共享内存。普通文件被映射到进程地址空间后,进程可以像访问普通内存一样对文件进行访问,不必再调用read(),write()等操作) 5.线性代数,随机数生成,以及傅里叶变换的功能。 Numpy 和pandas的dataframeNumPy是Python语言的一个扩充程序库。支持高级大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。 Pandas是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。Pandas提供了大量能使我们快速便捷地处理数据的函数和方法。 Numpy本身没有提供多少数据分析功能,但是理解Numpy数组以及面向数组的计算会有助于更加高效的使用pandas等科学计算和数据分析工具。 Numpy数组本篇我们将主要讨论数组对象ndarray以及如何创建一个数组对象。 (1)ndarray对象numpy当中的数组是一个ndarray对象,ndarray对象是用于存放同类型元素的多维数组,是numpy中的基本对象之一,另一个是func对象。ndarray 中的每个元素在内存中都有相同存储大小的区域,而且 Numpy 就是 C 的逻辑, 创建存储容器 “Array” 的时候是寻找内存上的一连串区域来存放, 而 Python 存放的时候则是不连续的区域, 这使得 Python 在索引这个容器里的数据时不是那么有效率。
以下是一个例子,比较含有100万的整数的list和array全部乘以2的时间 In [7]: import numpy as np In [8]: my_arr = np.arange(1000000) In [9]: my_list = list(range(1000000))list对象和array数组对象中的元素全部乘以2. In [10]: %time for _ in range(10): my_arr2 = my_arr * 2 CPU times: user 20 ms, sys: 50 ms, total: 70 ms Wall time: 72.4 ms In [11]: %time for _ in range(10): my_list2 = [x * 2 for x in my _list] CPU times: user 760 ms, sys: 290 ms, total: 1.05 s Wall time: 1.05 s ndarray 内部由以下内容组成:一个指向数据(内存或内存映射文件中的一块数据)的指针。 数据类型或 dtype,描述在数组中的固定大小值的格子。 一个表示数组形状(shape)的元组,表示各维度大小的元组。 一个跨度元组(stride),其中的整数指的是为了前进到当前维度下一个元素需要"跨过"的字节数,默认创建array是以row即order=C方式创建,所以此处的跨度元组默认指的是每一行的字节数。 a = np.array([[0,1,2],[3,4,5],[6,7,8]], dtype=np.float32)
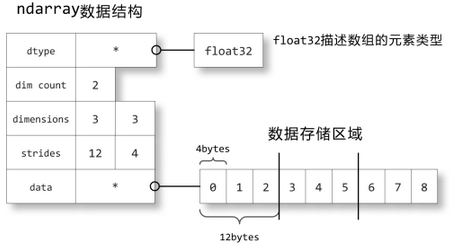
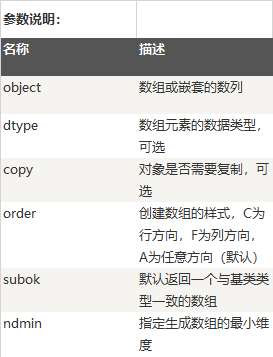
数据存储区域保存着数组中所有元素的二进制数据,dtype对象则知道如何将元素的二进制数据转换为可用的值。数组的维数、大小等信息都保存在ndarray数组对象的数据结构中。 strides中保存的是当每个轴的下标增加1时,数据存储区中的指针所增加的字节数。例如图中的strides为12,4,即第0轴的下标增加1时,数据的地址增加12个字节:即a[1,0]的地址比a[0,0]的地址要高12个字节,正好是3个单精度浮点数的总字节数;第1轴下标增加1时,数据的地址增加4个字节,正好是单精度浮点数的字节数 (2)创建ndarray创建一个 ndarray 只需调用 NumPy 的 array 函数即可: numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
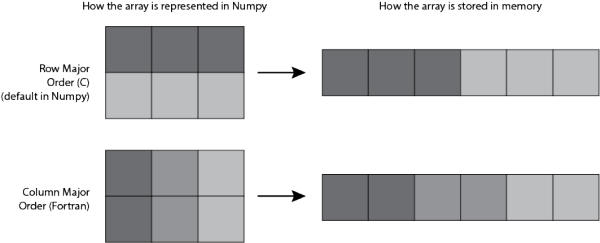
特别需要解释的是order,在我们看来的 2D Array, 如果追溯到计算机内存里, 它其实是储存在一个连续空间上的. 而对于这个连续空间, 我们如果创建 Array 的方式不同, 在这个连续空间上的排列顺序也有不同. 这将影响之后所有的事情! 我们后面会用 Python 进行运算时间测试. 在 Numpy 中, 创建 2D Array 的默认方式是 “C-type” 以 row 为主在内存中排列, 而如果是 “Fortran” 的方式创建的, 就是以 column 为主在内存中排列
a = np.zeros((200, 200), order='C') b = np.zeros((200, 200), order='F') N = 9999 def f1(a): for _ in range(N): np.concatenate((a, a), axis=0) def f2(b): for _ in range(N): np.concatenate((b, b), axis=0) t0 = time.time() f1(a) t1 = time.time() f2(b) t2 = time.time() print((t1-t0)/N) # 0.000040 print((t2-t1)/N) # 0.000070
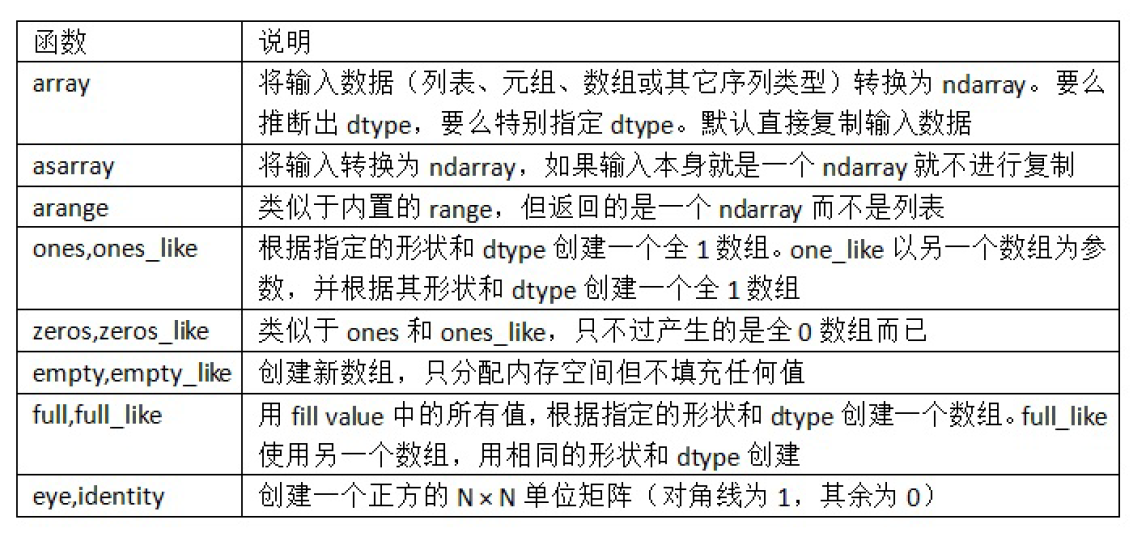
row 为主的存储方式, 如果在 row 的方向上合并矩阵, 将会更快. 因为只要我们将思维放在 1D array 那, 直接再加一个 row 放在1D array 后面就好了, 所以在上面的测试中, f1 速度要更快. 但是在以 column 为主的系统中, 往 1D array 后面加 row 的规则变复杂了, 消耗的时间也变长. 如果以 axis=1 的方式合并, “F” 方式的 f2 将会比 “C” 方式的 f1 更好。 创建数组的其他方式:np.zeros,np.empty,np.ones 都可以分别用来创建全为0的数组,为空的数组(只分配内存空间不赋值),全为一的数组等。 In [29]: np.zeros(10) Out[29]: array([ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0. ]) In [30]: np.zeros((3, 6)) Out[30]: array([[ 0., 0., 0., 0., 0., 0.], [ 0., 0., 0., 0., 0., 0.], [ 0., 0., 0., 0., 0., 0.]]) In [31]: np.empty((2, 3, 2)) Out[31]: array([[[ 0., 0.], [ 0., 0.], [ 0., 0.]], [[ 0., 0.], [ 0., 0.], [ 0., 0.]]])下表列出了其他的一些用于创建数组的函数
NumPy 数据类型 numpy 支持的数据类型比 Python 内置的类型要多很多,基本上可以和 C 语言的数据类型对应上,其中部分类型对应为 Python 内置的类型。下表列举了常用 NumPy 基本类型。 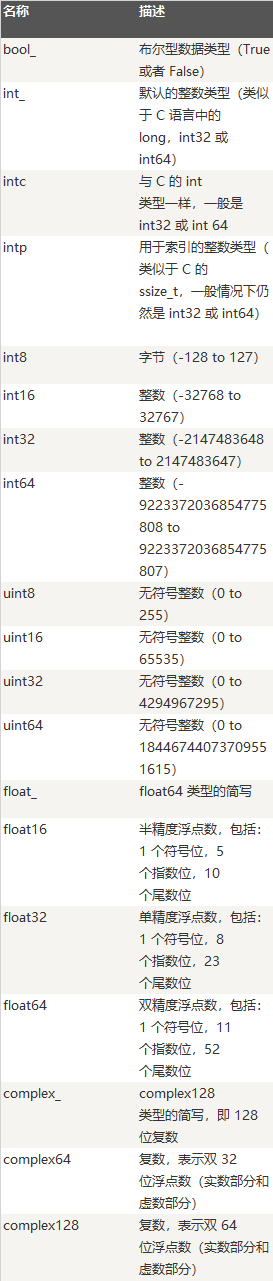
对于narray对象的dtype定义有两种方式,一种是在创建时,第二种是使用astype函数进行修改,当你创建numpy的数组对象且没有指定dtype,np.arrary会尝试为这个新建的数组推断出一个合适的类型,因为ndarray面向的是数值运算,默认创建的类型都是float64(浮点数)。 使用astype方法进行转换: In [37]: arr = np.array([1, 2, 3, 4, 5]) In [38]: arr.dtype Out[38]: dtype('int64') In [39]: float_arr = arr.astype(np.float64) In [40]: float_arr.dtype Out[40]: dtype('float64')
|
【本文地址】